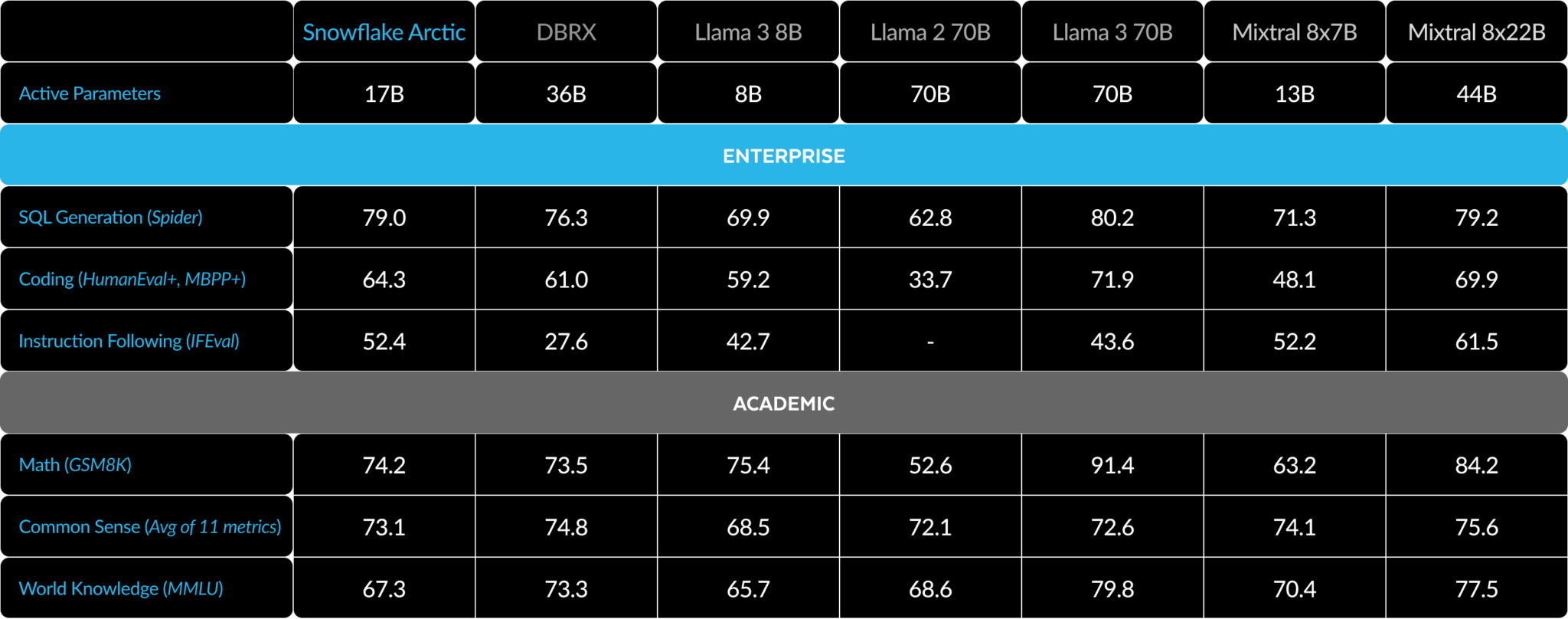
Where do you see that? This comparison[0] shows it outperforming Llama-3-8B on 5 out of 6 benchmarks. I'm not going to claim that this model looks incredible, but it's not that easily dismissed for a model that has the compute complexity of a 17B model.
{kind=link}